The plan
Use Simon Williamson’s Datasette tools — and maybe the rest of and maybe the rest of Datasette too — to replace an existing data script and perhaps gain new insight into site contents.
Also: puttering is fun.
Background
I incorporated in my site workflow a while back because of fRew Schmidt. See, he wrote an interesting post about his Hugo / Unix / Vim blogging workflow. I immediately copied q, a Perl script he wrote for querying site metadata via an in-memory SQLite database.
q is ridiculously fast and convenient if you know the query you want to ask.
$ q --sql 'select count(1) from articles where title like "%perl%"'
22
$ q --sql 'select count(1) from articles where title like "%python%"'
25
Is your query too awkward to comfortably type on a command line? Put it in a shell script, like fREW’s tag-count example.
#!/bin/bash
exec scripts/q \
--sql 'SELECT COUNT(*) AS c, tag FROM _ GROUP BY tag ORDER BY COUNT(*), tag' \
--formatter 'sprintf "%3d %s", $r{c}, $r{tag}'That gets you a list of all the tags in your entries, ordered by number of appearances.
$ tag-count
⋮
29 ruby
33 perl
38 python
43 learn
45 drawing
77 site
I converted it to Python eventually, of course. Records produced nice-looking output while letting me stick to SQL syntax. Noticeably slower than q, but acceptable. A bit later, I added a table for aliases. Then, another table for announcements — my tweets and toots about new content.
Aside from answering idle questions like “how many drawings have I posted?” my little database streamlines the process of publishing site updates and automatically announcing new posts.
What’s the problem?
I’m thinking about adding more tables to improve IndieWeb integration. But to be honest, my creation has grown unwieldy. And slow.
$ time query 'select date, title from articles order by date'
⋮
Skinny Lines and Flat Colors |2020-05-02T21:11:00-07:00
Pondering My Indieweb Guinea Pig |2020-05-03T20:30:00-07:00
Got a Working glitch-soc Rails Dev Environment |2020-05-04T23:26:21-07:00
445 rows
query 'select title, published_at from contents order by published_at' \
2.64s user 0.13s system 101% cpu 2.730 total
Compared to the original Perl script?
$ time q --sql 'select date, title from articles where date is not null is not null order by date'
⋮
2020-05-02T21:11:00-07:00 Skinny Lines and Flat Colors
2020-05-03T15:46:00-07:00 Sending Webmentions
2020-05-03T20:30:00-07:00 Pondering My Indieweb Guinea Pig
2020-05-04 23:26:21-07:00 Got a Working glitch-soc Rails Dev Environment
q --sql 0.17s user 0.02s system 99% cpu 0.197 total
I’m tempted to gut my Python workflow. Start fresh from q and Perl again. But no. That would be a lot of work — duplicated work, at that.
I’ll stick to Python for now. But surely we can do better than the duct tape script I’ve been using.
Simon Willison’s sqlite-utils may be just the thing.
What’s sqlite-utils?
sqlite-utils provides both a Python library and a command
line too for building and querying SQLite databases. It can guess a schema from
structures as you insert them — though you can be explicit if you prefer. It’s
particularly useful for bulk inserting or exporting data dumps in JSON or CSV.
Makes sense. It’s part of the Datasette ecosystem. Willison’s Datasette project simplifies exploring and publishing data for folks who understand data but not necessarily databases.
And although it’s slower than q for SQL queries, it’s much closer than what I came up with!
$ time sqlite-utils site.db 'select publishDate, title from entries order by publishDate' --table
⋮
2020-05-03T04:11:00+00:00 Skinny Lines and Flat Colors
2020-05-03T22:46:00+00:00 Sending Webmentions
2020-05-04T03:30:00+00:00 Pondering My Indieweb Guinea Pig
2020-05-05T06:26:21+00:00 Got a Working glitch-soc Rails Dev Environment
sqlite-utils site.db --table 0.54s user 0.16s system 158% cpu 0.442 total
Creating site.db with sqlite-utils
Okay! Let’s do this. I want to load and prepare details from my content entries before I let sqlite-utils turn it into a database.
Getting metadata from Hugo and front matter
We could recursively walk through the content/ folder, collecting front matter details about everything we find. Most of the time, this is more than I want. Hugo site organization includes supplemental material like page bundles and _index pages. That’s distracting when I only want to focus on my posts and notes. If you just want core content — posts, pages, stuff like that — ask Hugo.
I mentioned the hugo list commands before. hugo list all prints summaries of all your main content entries, as comma-separated text. Python’s standard subprocess and csv are all I need to turn that into something useful.
import csv
import subprocess
def list_hugo_content():
"""Return a listing of hugo content entries"""
result = subprocess.run(
["hugo", "list", "all"], capture_output=True, text=True, check=True
).stdout
return csv.DictReader(result.split("\n"))csv.DictReader gives me a collection of manageable dictionaries.
{
'date': '2020-04-28T01:36:54-07:00',
'draft': 'false',
'expiryDate': '0001-01-01T00:00:00Z',
'path': 'content/post/2020/04/from-dotfiles-to-org-file/index.adoc',
'permalink': 'https://randomgeekery.org/post/2020/04/from-dotfiles-to-org-file/',
'publishDate': '2020-04-28T01:36:54-07:00',
'slug': '',
'title': 'From Dotfiles to Org File',
}That’s useful for a high level overview of that post, but I want more. I want tags, categories, aliases, etc. I keep those details as YAML text in content front matter.
title: From Dotfiles to Org File
uuid: f03e5f2f-70a8-4988-92cd-595c8e3fdc97
description: at 1:30am they're all good ideas
year: '2020'
date: '2020-04-28 01:36:54-07:00'
tags:
- emacs
- shell
- org
draft: false
categories:
- Tools
aliases:
- /2020/04/28/from-dotfiles-to-org-file/
announcements:
mastodon: https://hackers.town/@randomgeek/104075340897518607
twitter: https://twitter.com/brianwisti/status/1255056188087111681PyYAML moves quick when powered by libYAML. So I make sure I have both installed on my Manjaro machine.
$ pamac install libyaml
$ pip install pyyaml
I can’t think of a pretty way to get at an entry’s front matter, so let’s just get it out of the way.
NOTE
It’s not worth rewriting a whole blog post just yet, but in the years since writing this I use python-frontmatter to handle frontmatter.
import yaml
DELIMITER = "---\n"
def get_frontmatter(filename):
"""Get dictionary from a file's YAML frontmatter"""
_, yaml_text, _ = open(filename).read().split(DELIMITER, maxsplit=2)
return yaml.safe_load(yaml_text)- read the file
- grab the front matter YAML
- hand back a dictionary based on that front matter text
Why a function? It’s only a couple lines of code.
Sure, but it’s an ugly couple of lines. Plus it hides the YAML-specific details away in case I switch my front matter to TOML, JSON, or some other format.
Okay, now to mash entry and relevant front matter bits together. I prefer Arrow ’s interface to datetime.
$ pip install arrow
from collections import namedtuple
import os
import arrowSiteEntry = namedtuple("SiteEntry", ["entry", "tags", "announcements", "aliases"])
def prepare_entry(entry):
"""Return a SiteEntry with details about a single content entry"""
path = entry["path"]
frontmatter = get_frontmatter(path)
entry["draft"] = True if entry.get("draft") == "true" else False
# Convert date strings to native datetime objects.
for f in ("date", "expiryDate", "publishDate"):
entry[f] = arrow.get(entry[f]).to("utc").datetime
sections = ("note", "post", "draft")
section_fragment = path.split(os.sep)[1]
entry["section"] = section_fragment if section_fragment in sections else None
# Extract important fields from frontmatter
simple_fields = ("caption", "category", "description", "series")
for field in simple_fields:
entry[field] = frontmatter.get(field)
tags = [{"entry_path": path, "tag": tag} for tag in frontmatter.get("tags", [])]
announcements = [
{"entry_path": path, "service": service, "url": url}
for service, url in frontmatter.get("announcements", {}).items()
]
aliases = [
{"entry_path": path, "url": alias} for alias in frontmatter.get("aliases", [])
]
return SiteEntry(entry, tags, announcements, aliases)- A namedtuple helps when you want some structure but not a full class.
- Always make sure times are in UTC when saving to the database!
- Hugo determines sections from a file’s location under
content/, so let’s do the same. entry_pathwill help connect tags to entries when creating the database
I got everything tidy and pretty. We’re ready for the database.
Loading the data
$ pip install sqlite-utils
The sqlite-utils Python API ends up taking hardly any code at all, thanks partly to the work spent massaging the entries. You treat the database as a dictionary, with each table name as a field. Tables get created when you insert something.
I think we called that “autovivification” in Perl. It’s nice.
from sqlite_utils import DatabaseDB_NAME = "site.db"
def build_db():
"""Build the database"""
entries = []
tags = []
announcements = []
aliases = []
for entry in list_hugo_content():
site_entry = prepare_entry(entry)
entries.append(site_entry.entry)
tags += site_entry.tags
announcements += site_entry.announcements
aliases += site_entry.aliases
site = Database(DB_NAME, recreate=True)
site["entries"].insert_all(entries, pk="path")
site["tags"].insert_all(
tags, pk=("entry_path", "tag"), foreign_keys=[("entry_path", "entries")]
)
site["announcements"].insert_all(
announcements,
pk=("entry_path", "url"),
foreign_keys=[("entry_path", "entries")],
)
site["aliases"].insert_all(
aliases, pk="url", foreign_keys=[("entry_path", "entries")]
)- Rebuild the database from scratch every time this runs. Alternately, leave this out and
upsert_allto do an insert or update. - Setting
pathas the primary key, since every filename should be unique. - A tuple
pkspecifies a compound primary key — each pair must be unique. sqlite-utilshides the details of foreign keys in SQLite. Just use a list ofFIELD_NAME/TABLE_NAMEpairs.
All that works makes build_db a convenient starting point for build-db.py.
if __name__ == "__main__":
build_db()I could specify an in-memory database, but no. For the moment I’ll settle on creating a database file. That way I can more easily play with the sqlite-utils command line interface.
$ sqlite-utils tables site.db --counts --json-cols | python -m json.tool
[
{
"table": "entries",
"count": 467
},
{
"table": "tags",
"count": 1043
},
{
"table": "announcements",
"count": 299
},
{
"table": "aliases",
"count": 900
}
]
I’m content. But I’m also curious. What does my site metadata look like in Datasette?
Exploring site.db with Datasette
I don’t have any great insights here. I just wanted to look at the pretty tables. Played with metadata and checked out the results.
$ pip install datasette
⋮
$ datasette serve --metadata datasette.json site.db
The basic interface is pleasant enough, especially when you apply some CSS Of course, Niche Museums shows you can go a long ways past “some CSS” with Datasette.
Oh and more on the pleasant interface. It allows you to edit the SQL for your current view.
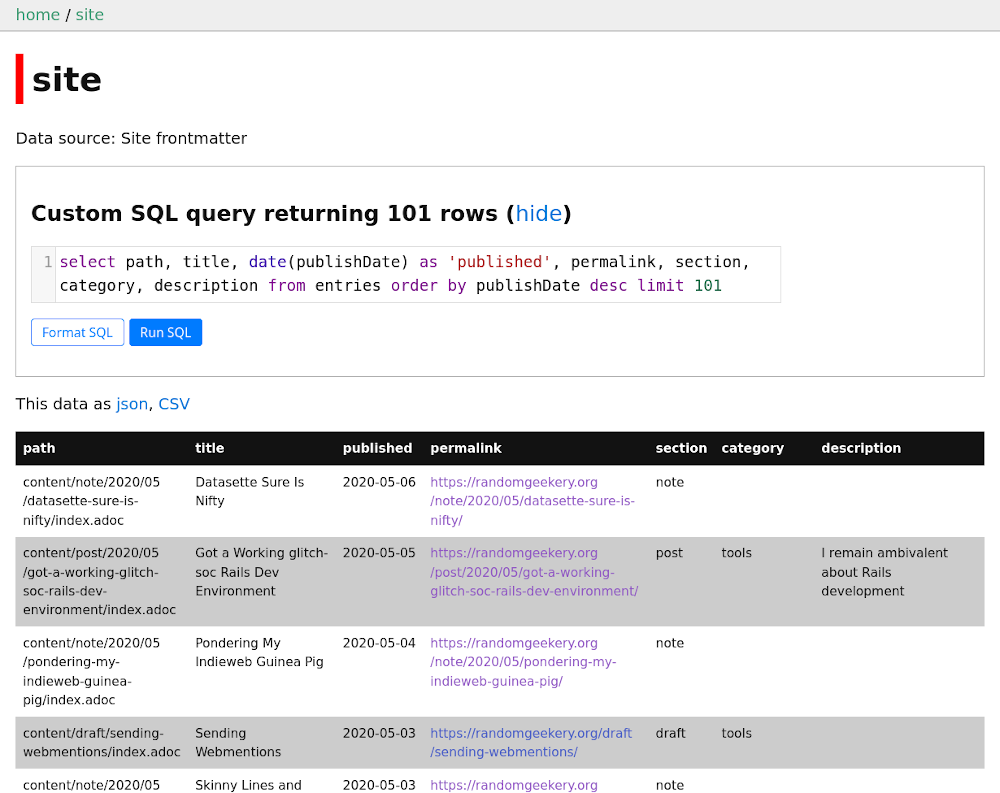
There are detail pages for each row. Again, the Niche Museums site shows that detail view can be heavily tweaked.
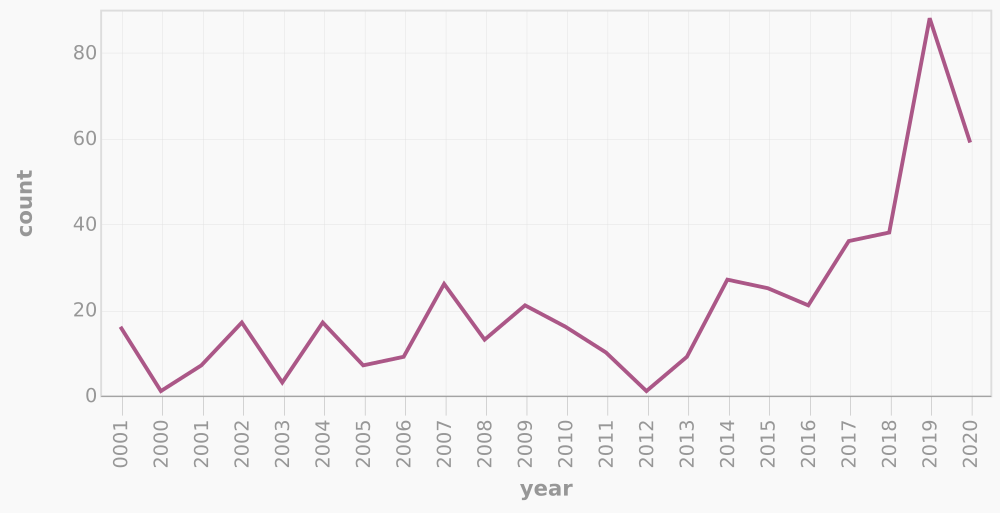
Plugins add all sorts of functionality. datasette-vega draws graphs of query results.
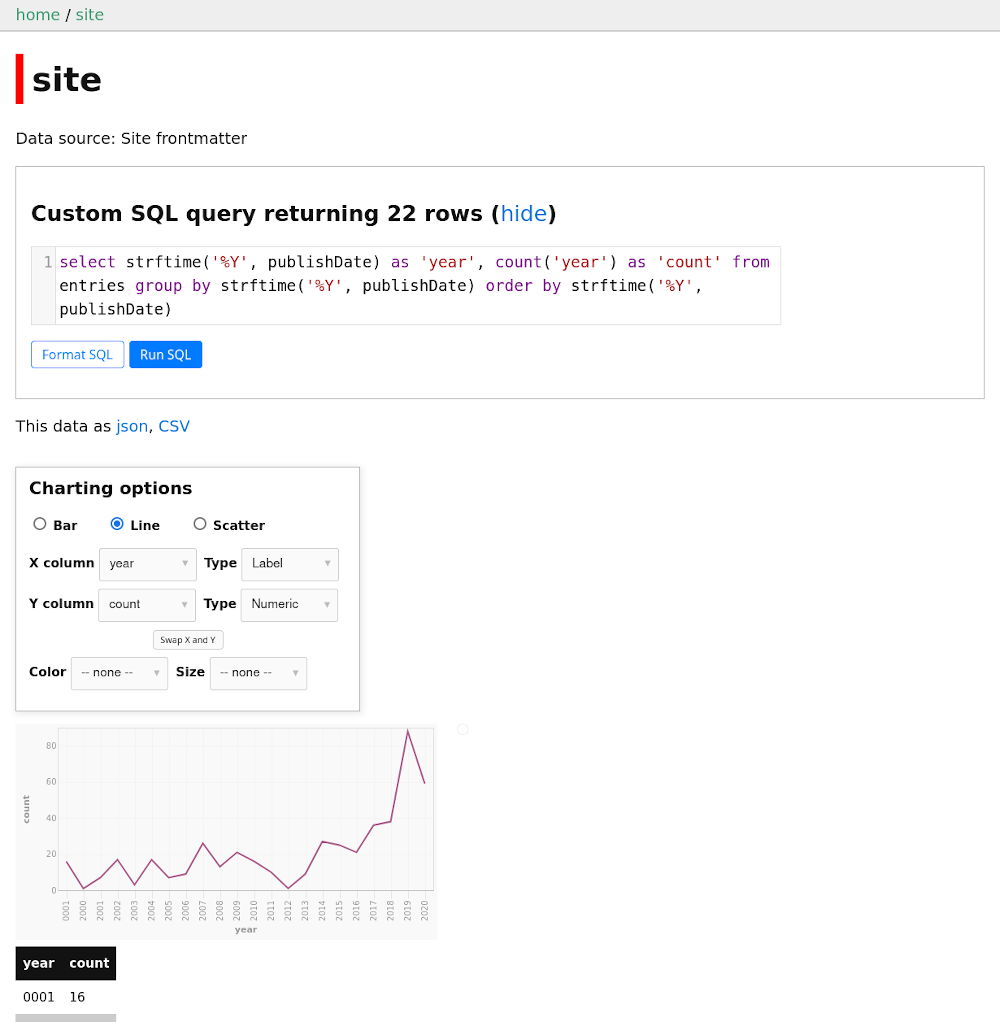
Year 0001? Hang on, let me check that in my shiny new Datasette server.
select
path,
title,
publishDate,
draft,
section,
category
from
entries
where
"publishDate" like '0001%'
order by
publishDate descYear 0001 content
| path | title | publishDate | draft | section | category |
|---|---|---|---|---|---|
content/about/index.adoc |
About | 0001-01-01T00:00:00+00:00 | 0 | ||
content/contact.adoc |
Contact | 0001-01-01T00:00:00+00:00 | 0 | ||
content/follow.adoc |
Follow | 0001-01-01T00:00:00+00:00 | 0 | ||
content/error.adoc |
uh oh | 0001-01-01T00:00:00+00:00 | 0 | ||
content/now/index.adoc |
Now | 0001-01-01T00:00:00+00:00 | 0 | ||
| …and a bunch of drafts | [redacted] | 0001-01-01T00:00:00+00:00 | 1 | draft | [redacted] |
Oh that’s right. Non-dated pages and drafts.
No I’m too embarrassed to share the full list. I get lots of ideas, okay? Then I’m afraid to throw any of them away. Sometimes they mutate. A couple months ago, this post was going to be about playing with hugo list in Python.
Yep. Datasette is pretty nifty. I’m not missing q at all. And I’m really not missing my Python query script.
What’s next?
That was fun! Still got a lot ahead of me.
- Figuring out the quickest way to refresh the database
- Adding those IndieWeb tables, so I can review Webmention updates
- New Pyinvoke tasks to build, query, and explore the database
- Fixing those tasks that still call out to my old and busted
queryPython - Make my Datasette site dashboard pretty
Explore
Check out some other datasettes available online!
- New York City Cultural Institutions
- Every mention of 2016 primary candidates in hip-hop songs
- the location of every tree in San Francisco — you need to page through to see all 189,144 locations
Backlinks
Got a comment? A question? More of a comment than a question?
Talk to me about this page on: mastodon
Added to vault 2024-01-15. Updated on 2024-02-02