
2018-06-02
Adjusted a couple clumsy property methods with
attr.Factorycallables for legibility.
The idea
I got an idea in my head a while ago to reduce image sizes for the site. Some of my drawings and photos are a little big. On a slower connection, a visitor could spend a while waiting. And if their bandwidth is metered? Oh I’d hate to think one of my sketches was what put their account over the cap, or got their account throttled to Edge speeds for the rest of the month.
I know I can make it better.
The problem with my idea
Well, I don’t really know. I suspect a handful of files are big, but how many files? How big? Big for who? And what about after I do the work? What is less than big? How will I know what work to do, and how will I know the effectiveness of what work when I’m done?
VM Brasseur gives excellent advice on many topics. One tip sticks in my head: I need numbers for my accomplishments. Heck, right now I need numbers to see if this accomplishment is necessary.
What numbers should I care about?
Of course the problem with data is that there is so much of it. What should I care about, if the goal is making a visit easier for visitors on limited connections?
File size
This is the more obvious and easily measured. This site (and most others) consists of files, right? Text files, image files, the occasional video file. All else being equal, a file that takes up more storage will also take more time to download.
“All else being equal” gets a little tricky though.
Latency
How long does it take for the user to see something useful when interacting with your site? (loading a page, clicking a link, doing things with web apps). It’s affected by – well, everything really. Network speed, server resources, sunspots.
If latency is high enough, one big file may reach a visitor quicker than a dozen small requests. If they spend too long waiting for too many pieces, they’ll go elsewhere in a heartbeat.
This Twitter thread by Andrew Certain provides an interesting look at how a large organization like Amazon takes latency seriously. It’s far deeper than I plan to measure, but it might help build more context.
Unfortunately latency can be hard to predict for one person with a blog. I do not yet know what tools work best for evaluating the effect of latency on site performance.
There are some easily found tools. Chrome and Firefox both include tools to “throttle” – simulating different network conditions.
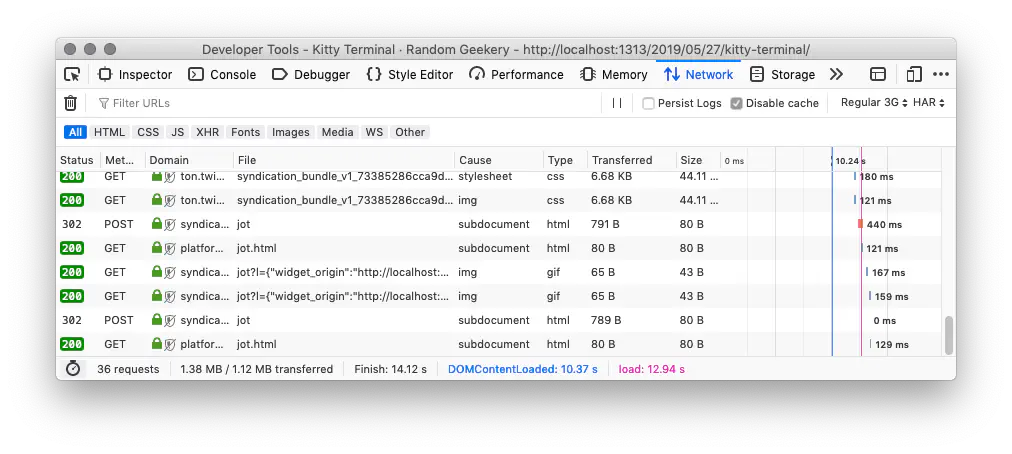
This is helpful on a page-by-page basis, and probably very helpful for evaluating a single page application. It doesn’t translate easily to checking an entire site. I suppose I could use Comcast, a command line tool for “simulating shitty network conditions” and maybe HTTPie to crawl the site under those conditions.
Brian, stop. This is taking you into the world of resilience testing and chaos engineering, which sounds awesome and has a wealth of tools already written. It also sounds completely unnecessary for this humble little blog.
“Pick your battles” is another truism that applies here.
We’ll ignore latency for now. Besides, I’ve already managed many major elements of latency. Hugo creates a static site. Every page already exists by the time you visit. No extra time needed for database lookups or constructing views. I use AWS S3 to host, and Cloudfront as a CDN. This is probably the fastest and most reliable approach possible with my resources.
I do have an issue with the CDN not promptly updating some files when I upload the site, but I’m working on that.
Measuring file sizes
I could just pick an arbitrary threshold and find every file bigger than that with a Perl one-liner using File::Find::Rule’s procedural flavor.
Code Sample
$ perl -MFile::Find::Rule -E 'say for find(file => size => "> 6M" => in => "public");'
public/2015/08/01/zentangle-doodle/cover.png
public/2017/04/22/kalaidoscope-symmetry/cover.jpg
public/2017/11/07/something-colorful/cover.jpg
public/2019/04/14/psychedelic-playing-card/cover.png
public/2018/09/30/cougar-mountain/fantastic-erratic.jpg
public/2018/09/30/cougar-mountain/old-stump.jpg
public/2018/09/30/cougar-mountain/mossy.jpg
public/2018/09/30/cougar-mountain/tall-stump.jpg
public/2018/09/30/cougar-mountain/cover.jpg
Or maybe find the median between my biggest and smallest files, flagging everything bigger than the median. I promised Python in the title, so let’s move away from Perl.
median.py
Code Sample
import os
import attr
@attr.s(auto_attribs=True)
class FileWeight:
"""Knows how much a file weighs"""
path: str
size: int
if __name__ == '__main__':
files_seen = []
for root, _, files in os.walk("public"):
for filename in files:
filepath: str = os.path.join(root, filename)
filesize: int = os.path.getsize(filepath)
files_seen.append(FileWeight(filepath, filesize))
smallest: int = min(files_seen, key=lambda fw: fw.size)
largest: int = max(files_seen, key=lambda fw: fw.size)
median: float = (smallest.size + largest.size) / 2
biggest_half = [f for f in files_seen if f.size > median]
for fw in biggest_half:
print(fw)
I know Python 3.7 has data classes. I like attrs, which supports type hinting while still working on older versions of the language.
Running this gives me the same files as my one-liner. Good choice for an arbitrary number, right?
Code Sample
$ python median.py
FileWeight(path='public/2015/08/01/zentangle-doodle/cover.png', size=8964751)
FileWeight(path='public/2017/04/22/kalaidoscope-symmetry/cover.jpg', size=7729604)
FileWeight(path='public/2017/11/07/something-colorful/cover.jpg', size=9594815)
FileWeight(path='public/2019/04/14/psychedelic-playing-card/cover.png', size=13088396)
FileWeight(path='public/2018/09/30/cougar-mountain/fantastic-erratic.jpg', size=7114429)
FileWeight(path='public/2018/09/30/cougar-mountain/old-stump.jpg', size=7672471)
FileWeight(path='public/2018/09/30/cougar-mountain/mossy.jpg', size=6639527)
FileWeight(path='public/2018/09/30/cougar-mountain/tall-stump.jpg', size=7052340)
FileWeight(path='public/2018/09/30/cougar-mountain/cover.jpg', size=8412560)
I learned that this technique of grabbing everything on one side of the median is called a “median split.” I also learned that however convenient it might be, a median split doesn’t mean anything. It’s the value halfway between two numbers. Is it a big download size? Maybe. What if I have a bunch of 5.9MB files? Those would be kind of big too, right? If I keep optimizing the biggest half and the median steadily moves down, how will I know when I’m done? What’s a small download?
Okay. I’m okay. I need to breathe for a minute. Once you start asking questions, it can be hard to stop.
So I need to know what the numbers mean, and what a good threshold is. Come to think of it, there might be a few thresholds.
Estimating download time
I care about how long it takes to download a file, assuming latency is as good as it’s going to get. The file size is one part of the download question. The visitor’s connection is the other part. I usually have a nice high speed connection, but not always.
Often I’m on LTE with one bar. Sometimes I’m on 3G. Very occasionally I find a dark corner that only gets me an Edge connection.
Sometimes I have no connection at all, but site optimization can’t help with that.
The Firefox throttling tool documentation includes a chart specifying what its selections represent. I know from site analytics that a third of my visitors use mobile devices. I don’t know what their connection speed is, but I find myself on 3G often enough that I think “Regular 3G” is an acceptable choice.
That 750 Kbps number represents 750,000 bits. There are eight bits in a byte. Divide 750,000 by eight and that’s only 93,750 bytes per second. The site’s median size of roughly six megabytes suddenly feels a lot bigger.
Let’s teach the FileWeight class to estimate downloads. I’ll clarify its printed details while I’m at it.
download-time.py
import os
import attr
DOWNLOAD_SPEED: int = 750_000 # bits per second
def describe_size(byte_count: int) -> str:
"""Use common notation to describe a byte count"""
scales = ((1024 * 1024 * 1024, "GB"), (1024 * 1024, "MB"), (1024, "KB"))
for multiple, name in scales:
if byte_count > multiple:
converted = byte_count / multiple
return f"{converted:.2f} {name}"
return f"{byte_count} bytes"
@attr.s(auto_attribs=True)
class FileWeight:
"""Knows how much a file weighs"""
path: str
size: int
def download_time(self, bps: int) -> float:
"""How many seconds to download this file at a given rate"""
bytes_per_second: float = bps / 8
return self.size / bytes_per_second
def __str__(self) -> str:
size = describe_size(self.size)
time_3g = self.download_time(DOWNLOAD_SPEED)
return f"<{self.path}> ({size}) 3g={time_3g:.3f}s"
if __name__ == '__main__':
# ...
The script is still focusing on the median, but the extra information should give us a little context.
Code Sample
$ python download-time.py
<public/2015/08/01/zentangle-doodle/cover.png> (8.55 MB) 3g=95.624s
<public/2017/04/22/kalaidoscope-symmetry/cover.jpg> (7.37 MB) 3g=82.449s
<public/2017/11/07/something-colorful/cover.jpg> (9.15 MB) 3g=102.345s
<public/2019/04/14/psychedelic-playing-card/cover.png> (12.48 MB) 3g=139.610s
<public/2018/09/30/cougar-mountain/fantastic-erratic.jpg> (6.78 MB) 3g=75.887s
<public/2018/09/30/cougar-mountain/old-stump.jpg> (7.32 MB) 3g=81.840s
<public/2018/09/30/cougar-mountain/mossy.jpg> (6.33 MB) 3g=70.822s
<public/2018/09/30/cougar-mountain/tall-stump.jpg> (6.73 MB) 3g=75.225s
<public/2018/09/30/cougar-mountain/cover.jpg> (8.02 MB) 3g=89.734s
Oh that’s not good. The biggest file would take almost two and a half minutes to download, while the smallest above the median would still take over a minute. That’s on top of whatever else is on the page.
My threshold should be far less than the median. How much less?
Picking my thresholds
Jakob Nielsen summarized how different response times feel to a user when interacting with an application – and yes, loading a post from your blog in a browser is interacting with an application, affected by the browser and your site (and the network, and so on).
- less than 0.1 seconds is fast enough that it feels like they’re doing it themselves
- less than 1 second is slow enough that it feels like they’re telling the computer to do something
- less than 10 seconds is so slow that you’re starting to lose their attention
Beyond ten seconds and you’re wrestling with the limits of a normal human brain that already has plenty of stuff to think about.
I can and do make excuses –
- “They probably came here on purpose, so they’ll wait!”
- “This is so cool that they won’t mind waiting!”
- “So many factors are beyond my control that there’s no point worrying about it.”
- “Everybody else’s site is even worse!”
No. The first two are lies from my ego, the last two are terrible arguments from my apathy.
I know my thresholds. Let’s teach FileWeight about them so it can report the news.
Code Sample
# ...
DOWNLOAD_EXPRESSIONS = {
"excessive": "🙁",
"slow": "😐",
"ok": "😊",
"instant": "😁"}
@attr.s(auto_attribs=True)
class FileWeight:
# ...
def __str__(self) -> str:
size = describe_size(self.size)
time_3g = self.download_time()
describe_3g = f"{time_3g:.3f}s"
if self.is_excessive():
describe_3g += DOWNLOAD_EXPRESSIONS["excessive"]
elif self.is_slow():
describe_3g += DOWNLOAD_EXPRESSIONS["slow"]
elif self.is_ok():
describe_3g += DOWNLOAD_EXPRESSIONS["ok"]
elif self.is_instant():
describe_3g += DOWNLOAD_EXPRESSIONS["instant"]
return f"<{self.path}> ({size}) 3g={describe_3g}"
def is_excessive(self) -> bool:
return self.download_time() > 10.0
def is_slow(self) -> bool:
return 1.0 < self.download_time() <= 10.0
def is_ok(self) -> bool:
return 0.1 < self.download_time() <= 1.0
def is_instant(self) -> bool:
return self.download_time() <= 0.1
if __name__ == '__main__':
files_seen = []
for root, _, files in os.walk("public"):
for filename in files:
filepath: str = os.path.join(root, filename)
filesize: int = os.path.getsize(filepath)
files_seen.append(FileWeight(filepath, filesize))
# I got bored of looking at the same files
import random
selection = random.sample(files_seen, 10)
for fw in selection:
print(fw)
I also added a little emoji quick reference so I can tell at a glance the expected user reaction at the file’s download rate.
Code Sample
$ python download-time.py
<public/2018/12/31/hopepunk-for-2019/cover_hu302a359ad2f64a42481affbc4fbbb8c4_4191368_1000x0_resize_q75_linear.jpg> (156.96 KB) 3g=1.714s😐
<public/2018/10/27/winter-hat-and-gloves/cover_hu42513aeed6d773f768448596f8f497f6_2320770_1000x0_resize_q75_linear.jpg> (182.43 KB) 3g=1.993s😐
<public/tags/pagetemplate/index.xml> (128.25 KB) 3g=1.401s😐
<public/2018/05/26/crafts-are-now-posts/index.html> (17.27 KB) 3g=0.189s😊
<public/2001/01/17/python/index.html> (6.44 KB) 3g=0.070s😁
<public/post/2013/fickle/index.html> (328 bytes) 3g=0.003s😁
<public/2018/08/11/satellite/satellite-lines-black.jpg> (476.27 KB) 3g=5.202s😐
<public/coolnamehere/2007/04/19_01-handling-a-single-round.html> (469 bytes) 3g=0.005s😁
<public/2018/08/19/island-center-forest/mossy-trees.jpg> (3.56 MB) 3g=39.789s🙁
<public/2008/10/01/natalies-hat/cover.jpg> (84.94 KB) 3g=0.928s😊
Plenty of build process artifacts in there. The long image names come from using Hugo image processing functions for thumbnails and inline images. I also have many tiny redirect files, letting Hugo aliasing behavior make up for the site’s inconsistent organization over time.
A FileWeight object can now describe the details I care about for a single file, including where it fits in the attention span thresholds. How many of my files are too big?
Putting it all together
Ideally I would measure all the files associated with each post – HTML, CSS, fonts, JavaScript if any, and images – then add those together for a total page weight. Someday I may even do that! Not today, though. Today I focus on information about downloading each file individually. This post is long enough already.
All the files
report-weight.py
Code Sample
from typing import List
# ...
def describe_speed(bit_count: int) -> str:
"""Use common notation to describe a baud rate"""
scales = ((1000 * 1000 * 1000, "Gbps"),
(1000 * 1000, "Mbps"), (1000, "Kbps"))
for multiple, name in scales:
if bit_count > multiple:
converted = bit_count / multiple
return f"{converted:.2f} {name}"
return f"{bit_count} bps"
# ...
@attr.s(auto_attribs=True)
class SiteWeight:
"""Reports download information for all files in the site"""
public_dir: str
files: List[FileWeight] = attr.ib(
init=False, default=attr.Factory(
lambda self: self._load_files(), takes_self=True))
def _load_files(self) -> List[FileWeight]:
"""Gather FileWeight info for every visible file on the site"""
files_seen = []
for root, _, files in os.walk(self.public_dir):
for filename in files:
filepath: str = os.path.join(root, filename)
filesize: int = os.path.getsize(filepath)
files_seen.append(FileWeight(filepath, filesize))
return files_seen
def _build_download_table(self) -> List:
"""Build cells of a download estimate table"""
excessive_count: int = len([f for f in self.files if f.is_excessive()])
slow_max = describe_size(10 * DOWNLOAD_SPEED / 8)
ok_max = describe_size(1 * DOWNLOAD_SPEED / 8)
instant_max = describe_size(0.1 * DOWNLOAD_SPEED / 8)
slow_count: int = len([f for f in self.files if f.is_slow()])
ok_count: int = len([f for f in self.files if f.is_ok()])
instant_count: int = len([f for f in self.files if f.is_instant()])
download_table = [
("excessive", "> 10s", f"> {slow_max}", excessive_count),
("slow", "1s - 10s", f"{ok_max} - {slow_max}", slow_count),
("ok", "0.1s - 1s", f"{instant_max} - {ok_max}", ok_count),
("instant", "≤ 0.1s", f"≤ {instant_max}", instant_count)
]
return download_table
def print_summary(self) -> None:
"""Format and display a summary of download estimates"""
print(f"All files in {self.public_dir}")
file_count = len(self.files)
total_bytes = sum([f.size for f in self.files])
total_size = describe_size(total_bytes)
print(f"{file_count:,} files ({total_size})")
speed = describe_speed(DOWNLOAD_SPEED)
print(f"Download guesses for {speed}")
download_table = self._build_download_table()
for name, description, size_range, count in download_table:
expression = DOWNLOAD_EXPRESSIONS[name]
print(f" {expression} {description: <10} {size_range: <26} {count: >6,}")
if __name__ == '__main__':
site = SiteWeight("public")
site.print_summary()
I spent too much time on that download table. I could have spent even more, sizing each column to the longest field and anyways that wasn’t the point. Let’s look at my download estimates.
Code Sample
$ python report-weight.py
All files in public
1,886 files (418.71 MB)
Download guesses for 750.00 Kbps
🙁 > 10s > 915.53 KB 111
😐 1s - 10s 91.55 KB - 915.53 KB 269
😊 0.1s - 1s 9.16 KB - 91.55 KB 611
😁 ≤ 0.1s ≤ 9.16 KB 895
Way too many files take more than ten seconds to load. I know better than to be pleased about the large number of files that load instantly. As I mentioned, quite a few of them are redirects. On the latency side of things those are worse because the visitor then has to load the real post.
I also said I’m not worrying about latency today.
The median list was helpful in showing me that my biggest offenders are image files, so what about adding a report on those?
Just the media files
The easiest way would be to base it off file extension. But that ends up looking a bit untidy, because extensions have accumulated over the years. JPEG files are the worst offender, being stored as .jpeg, .jpg, and even .JPG.
I’ll use the standard mimetypes library instead. FileWeight can use that to guess what kind of file it’s looking at, and SiteWeight will make another download table for media files. It still uses file extensions, but with a smarter list than what I could build.
weight-with-media.py
Code Sample
# ...
import mimetypes
# Tell mimetypes about nonstandard files it may find.
mimetypes.add_type("text/plain", '.map')
# ...
@attr.s(auto_attribs=True)
class FileWeight:
# ...
filetype: str = attr.ib(init=False, default=attr.Factory(
lambda self: self._guess_filetype(), takes_self=True))
def _guess_filetype(self) -> str:
mimetype, _ = mimetypes.guess_type(self.path, strict=False)
return mimetype
def is_media(self) -> bool:
"""is this an image or video?"""
return self.filetype.split("/")[0] in ("image", "video")
@attr.s(auto_attribs=True)
class SiteWeight:
# ...
def _build_download_table(self, files: List) -> List:
"""Build cells of a download estimate table"""
excessive_count: int = len([f for f in files if f.is_excessive()])
slow_max = describe_size(10 * DOWNLOAD_SPEED / 8)
ok_max = describe_size(1 * DOWNLOAD_SPEED / 8)
instant_max = describe_size(0.1 * DOWNLOAD_SPEED / 8)
slow_count: int = len([f for f in files if f.is_slow()])
ok_count: int = len([f for f in files if f.is_ok()])
instant_count: int = len([f for f in files if f.is_instant()])
download_table = [
("excessive", "> 10s", f"> {slow_max}", excessive_count),
("slow", "1s - 10s", f"{ok_max} - {slow_max}", slow_count),
("ok", "0.1s - 1s", f"{instant_max} - {ok_max}", ok_count),
("instant", "≤ 0.1s", f"≤ {instant_max}", instant_count)
]
return download_table
def summarize(self, files: List, description: str) -> str:
lines: List[str] = [
description
]
file_count = len(files)
total_bytes = sum([f.size for f in files])
total_size = describe_size(total_bytes)
lines.append(f"{file_count:,} files ({total_size})")
speed = describe_speed(DOWNLOAD_SPEED)
lines.append(f"Download guesses for {speed}")
download_table = self._build_download_table(files)
for name, description, size_range, count in download_table:
expression = DOWNLOAD_EXPRESSIONS[name]
lines.append(
f" {expression} {description: <10} {size_range: <26} {count: >6,}")
return "\n".join(lines)
def print_summary(self) -> None:
"""Format and display a summary of download estimates"""
print("---")
full_summary = self.summarize(self.files,
f"All files in {self.public_dir}")
print(full_summary)
print("---")
media_files = [f for f in self.files if f.is_media()]
media_summary = self.summarize(media_files,
f"Media files in {self.public_dir}")
print(media_summary)
if __name__ == '__main__':
# ...
The script makes two download reports now, with only a little more work!
Code Sample
$ python weight-with-media.py
---
All files in public
1,886 files (418.71 MB)
Download guesses for 750.00 Kbps
🙁 > 10s > 915.53 KB 111
😐 1s - 10s 91.55 KB - 915.53 KB 269
😊 0.1s - 1s 9.16 KB - 91.55 KB 611
😁 ≤ 0.1s ≤ 9.16 KB 895
---
Media files in public
802 files (392.19 MB)
Download guesses for 750.00 Kbps
🙁 > 10s > 915.53 KB 107
😐 1s - 10s 91.55 KB - 915.53 KB 236
😊 0.1s - 1s 9.16 KB - 91.55 KB 339
😁 ≤ 0.1s ≤ 9.16 KB 120
Yeah, that’s what I thought. The majority of those small files are text, and the vast majority of the large files are image or video. Yes, I noticed that a few of my excessively large files are text. Probably archive pages of one sort or another. I’ll gather the information on those later.
But it looks like I have an answer to my question.
My question?
Whether it’s worth my time to try optimizing image file sizes.
Oh right right. The answer?
The answer is “yes.”
Nearly half of my media files would be noticeably slow to download on a 3G connection. Over a hundred are large enough to stretch the patience of any visitor not blessed with a constant high speed pipe. That’s not very nice on my part.
Now I know I can make it better. Even better: with this script, I can ask the question again whenever I want!
Optimizing images is another post, though.
Could I improve my weighing script?
Of course! Here are some ideas I got while writing this, including a couple I included but removed to maintain focus.
- additional thresholds beyond “excessive” so I can determine how many files contribute to painfully long download times
- verbose mode to list file details on request
- options to estimate for different download rates
- more detail on media files, perhaps to see if compression has been applied and how much
- report base on page weight rather than individual file weight, to get a more realistic idea of visitor experience.
- format the list in JSON to simplify handing off to other reporting tools
- include median and mean file sizes for more number crunching goodness
- list the ten largest files, so I know where to focus my optimization efforts
Should I optimize my weighing script?
Good question! Let’s look at the numbers.
Code Sample
$ time make weight
python weight-with-media.py
...
real 0m0.131s
user 0m0.083s
sys 0m0.044s
No.
I assembled this in a few hours. Half of it’s too clever and the other half’s too stupid. But it gets the answers I need in a timely fashion. That’s plenty good enough.